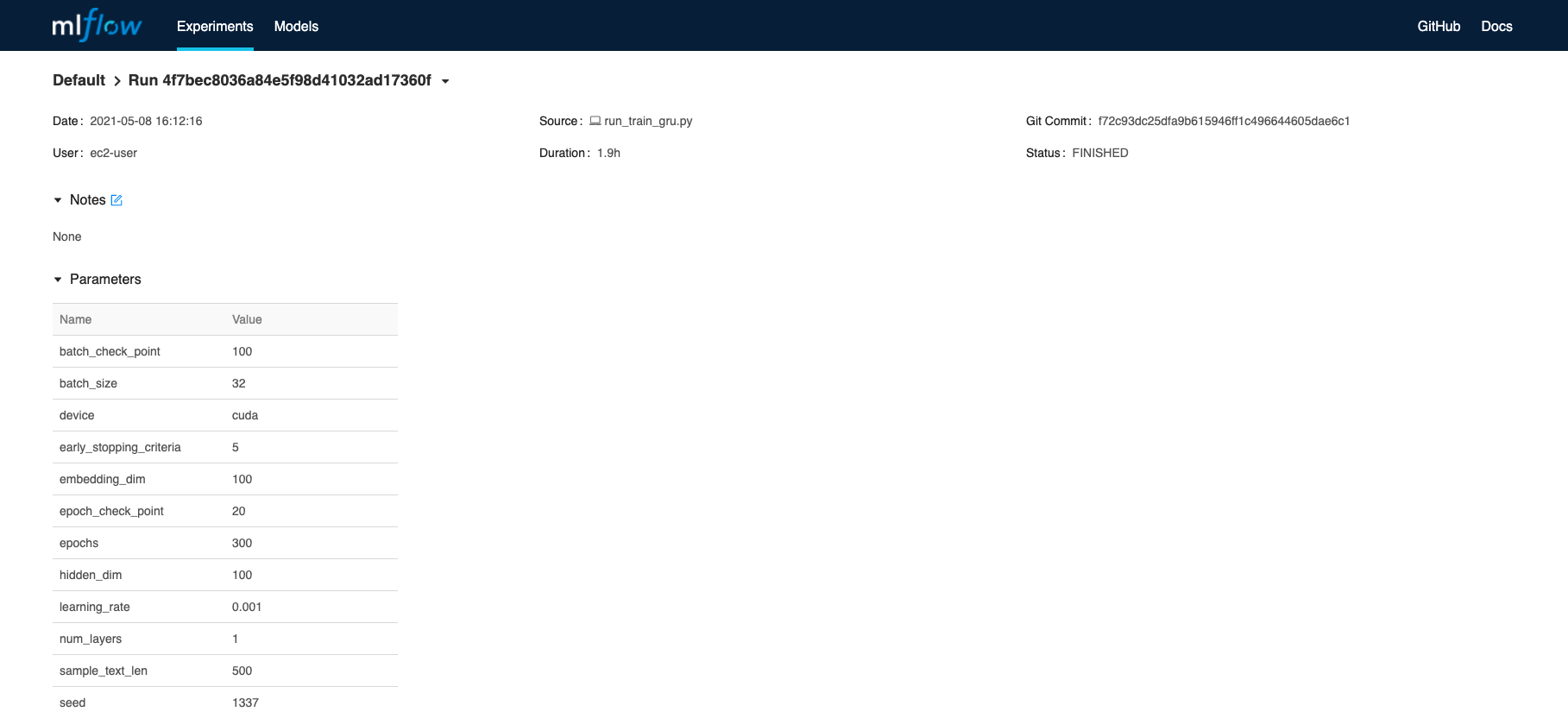
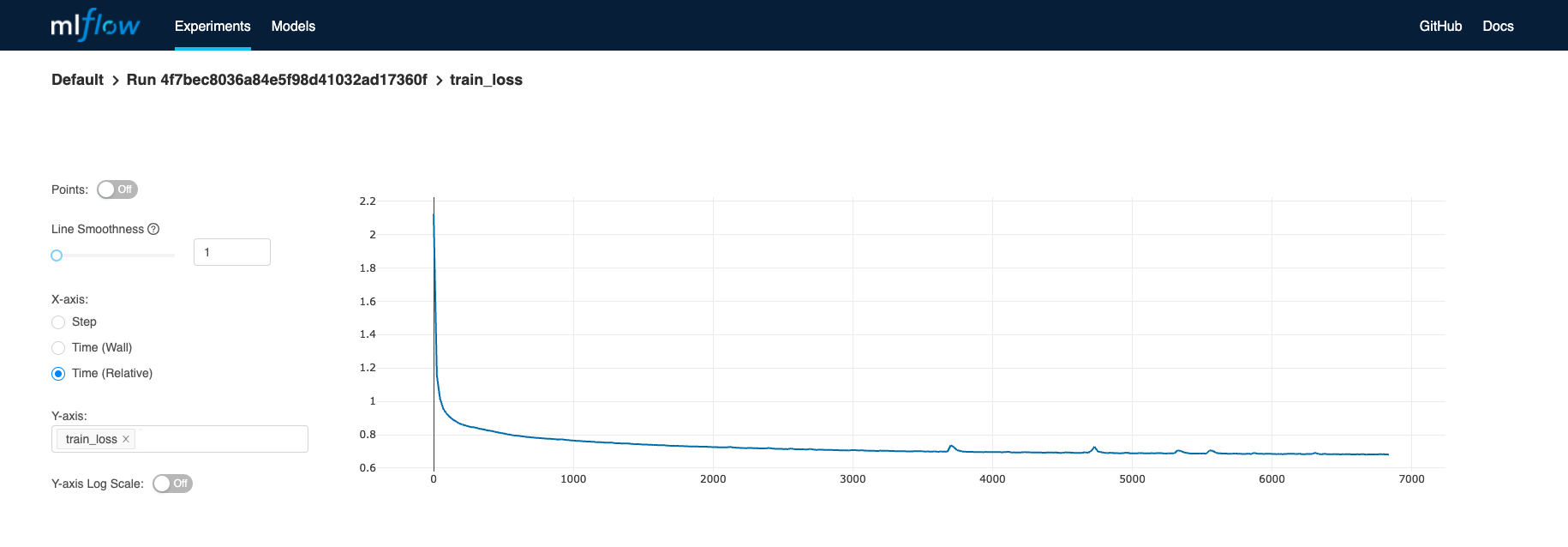
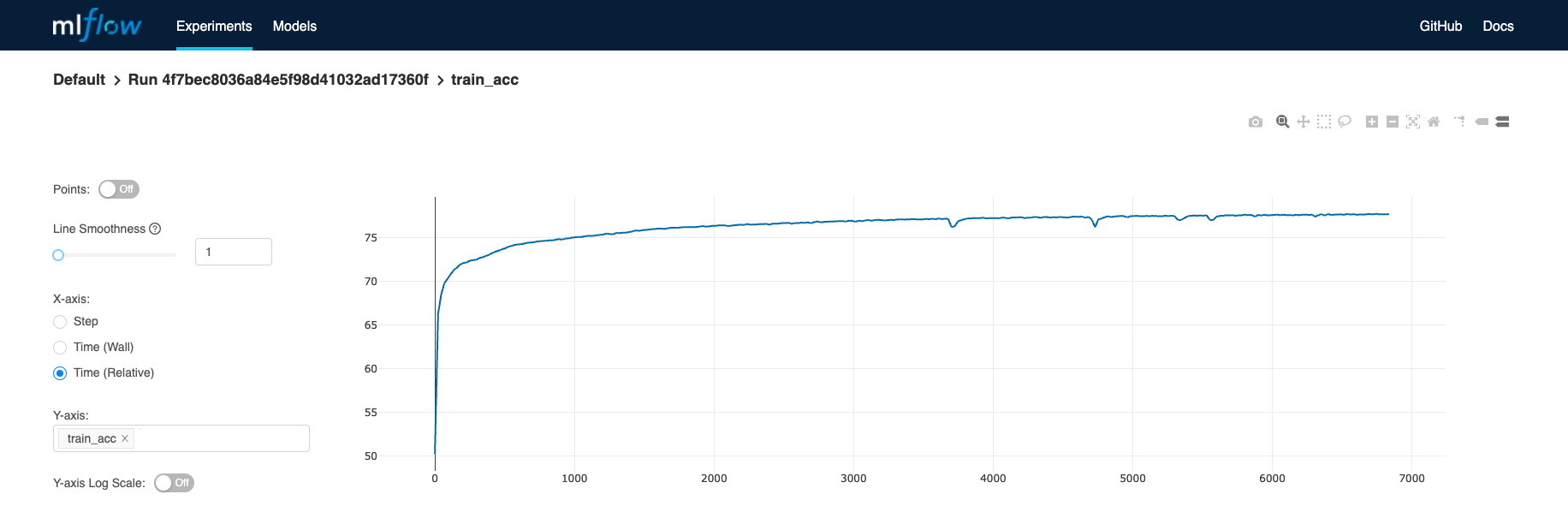
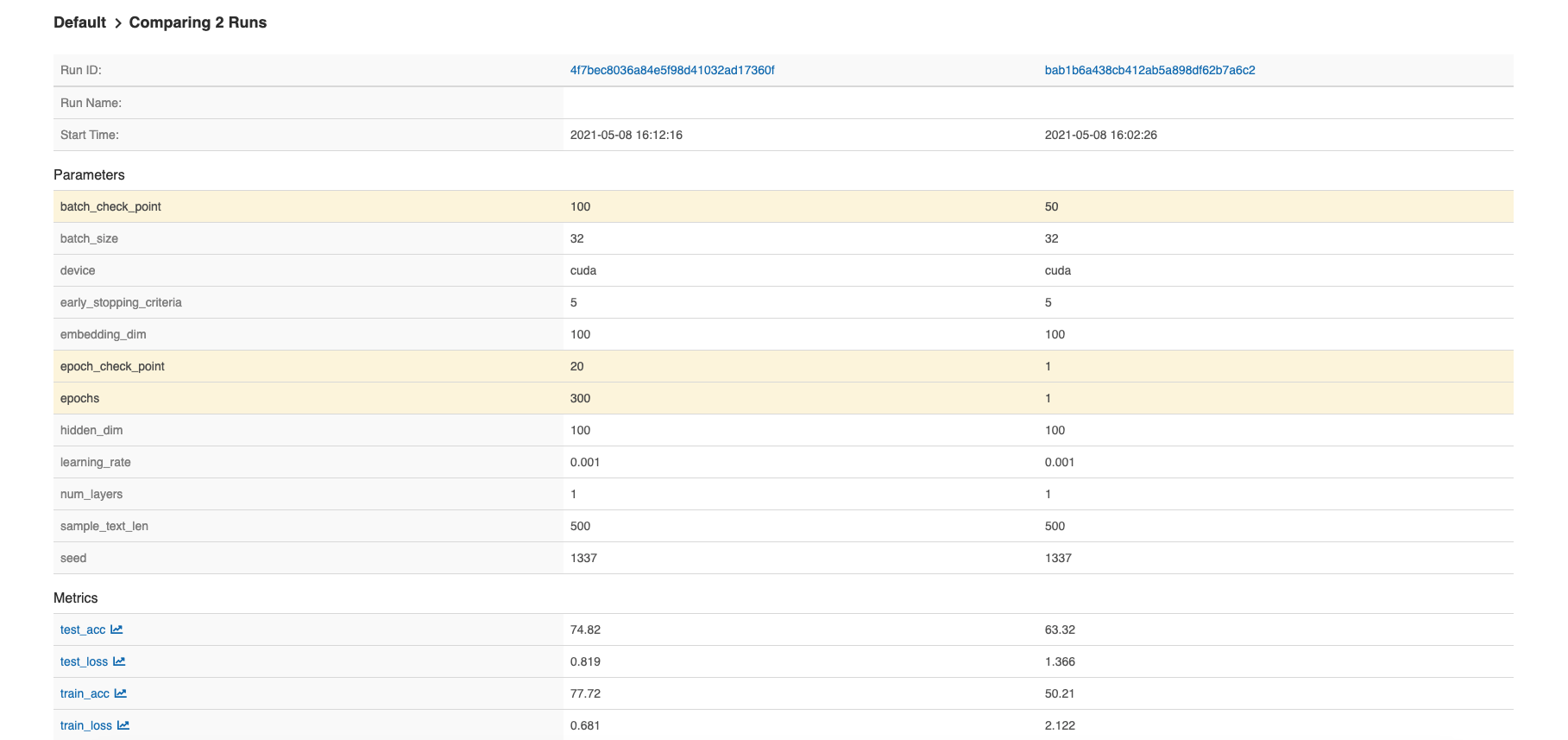
Building a Chatbot with LlamaIndex : Beyond Hello World

Image by Alexandra_Koch from Pixabay
Motivation
This series goes beyond the typical ‘Hello World’ tutorial to explore essential considerations for building real-world Generative AI applications. While there are excellent resources [1] [2] on best practices for building Generative AI systems, applying them in real implementations isn’t always clear. This series is for those who are already familiar with Large Language Models (LLMs), have some experience with basic tutorials, and are ready to take the next steps in building more realistic applications.
Through the series, we’ll use LlamaIndex and other tools to incrementally build a minimal Generative AI application while addressing key topics like LLM hallucinations, evaluations, monitoring, and retrieval-augmented generation (RAG).
Example Application
In this tutorial, we’ll build a simple Q&A chatbot using a fictitious product called RelMiner and its documentation. The chatbot will enable us to query the RelMiner documentation interactively, retrieving relevant information based on our questions.
Understanding your input data is crucial in Generative AI. For convenience, here is a small section of the docs, so you get familiar with RelMiner:
RelMiner is an open-source command-line tool designed to automatically extract a knowledge graph from a given text corpus. It detects entities, concepts, and relationships within unstructured text, making it ideal for researchers, data scientists, and knowledge engineers looking to structure textual data.
Reading the docs (relminer.txt) in more detail will help you assess better the model’s response quality.
Walkthrough the code
The first iteration of our chatbot is simple, and here are the key sections of the code.
1
2
3
4
llm = OpenAI(
model=MODEL_NAME,
system_prompt=system_prompt,
)
The LLM is created using the model name and the system prompt, which frames the personality and goal of the Chatbot. LlamaIndex supports many providers, in this case the OpenAI class, allows the Chatbot to use OpenAI for text generations.
The LLM is responsible for generating the final answer, given our question and relevant sections of our documentation. This technique of providing relevant context to the LLM along with the user query is called grounding, and is key to prevent model hallucinations and getting more accurate and relevant answers.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
data = SimpleDirectoryReader(input_dir=raw_data_dir).load_data()
# we use the storage context for persisting our index
storage_context = StorageContext.from_defaults()
"""
the in memory index that allows the chat engine to find relevant
pieces of content
"""
vector_index = VectorStoreIndex.from_documents(
data, show_progress=True, storage_context=storage_context
)
# saving the index for future use
vector_index.storage_context.persist(persist_dir=persistence_index_dir)
This section of the code, does three things:
- Loads the RelMiner’s documentation
- Creates a semantic index with the documentation
- Persists the the index for later use
Here we create an index using the RelMiner documentation, so the Chatbot can search and find the semantically relevant sections of the documentation for the given question.
LlamaIndex provides a SimpleDirectoryReader to load the documentation, and the VectorStoreIndex that breaks the documents into smaller sections called chunks, and creates a semantic index with these pieces. The VectorStore provides Retrieval Augmented Generation (RAG) which basically consist in finding semantically relevant pieces of documentation, given a user question.
Last, we persist the index so we avoid reconstructing it in subsequent runs.
1
2
3
4
5
chat_engine = vector_index.as_chat_engine(
chat_mode=chat_mode,
llm=llm,
verbose=True
)
Once the Index is created, we can use the convenient method as_chat_engine to get a fully initialized Chat Engine, capable of understanding our questions, finding the relevant information in the index, and invoking the LLM with the given context.
Chatbot test drive
Please following these instructions in the README.md to setup the Chatbot.
Let’s start with some basic “vibe checks” and see how the Chatbot answers our questions.
Now use this command to run the chatbot:
1
python iteration_0/chatbot.py --mode best --prompt v0
NOTE: Please keep in mind that you won’t get the same answers I got when running the Chatbot. The behavior might be different, specially in the first conversations. Hopefully, as you tweak the system you should get more relevant answers as described below.
Conversation 1
At this point we are using “best” chat mode, which means LlamaIndex uses the “openai” mode if you are using an OpenAI model that supports the latest function calling API, otherwise uses the “react” mode.
Question: What does relminer provides ?
RelMiner provides a set of tools and techniques for mining relationships from large datasets. It uses advanced algorithms to discover patterns and connections between different data points, which can be used for various purposes such as predictive analytics, customer segmentation, and network analysis. It can handle both structured and unstructured data, making it a versatile tool for data analysis.
At first glance, the answer looks reasonable, but is not really grounded on our documentation, and is just pure hallucination:
- According to our docs, RelMiner is just a command line tool, not “set of tools and techniques”
- The section “…mining relationships from large datasets” is not indicated in our docs.
- The docs don’t mention anything about “predictive analytics, customer segmentation”: which in this case it could make sense, but the subtle point here is that the output is not aligned with the documents.
If this Chatbot was about a refund policy, we could get in trouble given false information to our clients.
Question: What input formats does it support ?
I’m sorry for the confusion, but as an AI model developed by OpenAI, I don’t have specific information about the input formats supported by RelMiner. It would be best to refer to the official documentation or contact the developers for accurate information.
Here the model acknowledges it does not really know about RelMiner. Somehow the chat engine did not search for relevant documentation in the index, and did not ground the LLM with this context, leaving the LLM to rely on what it saw in its training data to come up with the answer.
Internally, the Chat Engine should have used a tool invocation, which allows it to search for the relevant context in the index, but the “best” chat mode did not force the Engine to do that.
Let’s ask again the same question, and see what happens.
Question: What input formats does relminer support ?
RelMiner supports various input formats including CSV, JSON, and XML. It can also accept data directly from databases such as MySQL, PostgreSQL, and MongoDB. Additionally, it can handle data from APIs and web scraping.
This is just another hallucination, as the documentation does not refer to any XML support, but HTML instead. Notice how the output varies with different wrong answers, as we repeat the questions.
Conversation 2
It turns out that, using a different type of chat mode can help to address these issues. Basically, we need to constrain the system to ground the LLM with the information provided in our documentation.
In order to do that, we can use either “context” or “condense_plus_context” chat mode, which basically forces the system to use the context for grounding the LLM. Let’s run again the Chatbot using this command.
1
python iteration_0/chatbot.py --mode condense_plus_context --prompt v0
Let’s see how the system behaves now.
Question: What does relminer provides ?
RelMiner is an open-source command-line tool that provides automated extraction of a knowledge graph from a given text corpus. It detects entities, concepts, and relationships within unstructured text. It supports multiple input formats like plain text, CSV, JSON, and HTML, and outputs structured graph data in formats such as RDF, JSON-LD, and CSV. It uses natural language processing (NLP) and machine learning techniques to identify entities and relationships. This makes it suitable for applications like semantic search, recommendation systems, and data integration.
This is much better, notice how the input and output formats supported by the tool are correct, as well as the general description of it.
Question: Which databases are supported by relminer ?
RelMiner does not directly support any specific types of databases. Instead, it processes input in various formats such as plain text, CSV, JSON, and HTML, and outputs structured graph data in formats like RDF, JSON-LD, and CSV. These output formats can then be imported into a variety of database systems that support them.
This is also good, as it answered that it does not support any types of databases.
Question: What are the main commands supported by relminer ?
The answer is omitted for brevity, but fundamentally it was correct and extracted from the index.
Question: Does relminer support the fusion of two knowledge graphs ?
The provided information does not mention any feature or functionality of RelMiner that supports the fusion of two knowledge graphs.
- This answer is good, and aligned with our documentation.
Question: Even if not documented, try to imagine how to use relminer to fuse two knowledge graphs ?
As a chatbot, I can only provide information based on the given document and I don’t have the ability to imagine or make assumptions. According to the provided document, there is no information about fusing two knowledge graphs using RelMiner. It would be best to refer to the official documentation or contact the developers for more accurate information.
- This answer is good, even after trying to coerce the model to provide an guessed answered.
Question: What are the pricing models for relminer ?
RelMiner is an open-source tool, which means it is free to use. There is no pricing model mentioned in the document. As with most open-source projects, you can use, modify, and distribute it freely. However, contributions to the project, such as bug reports, feature requests, or pull requests, are welcome.
This is mostly accurate, the only problem is that is going beyond what’s in our documentation, and talking about how open source projects work in general, which might or might not be true in our case. Let’s assume, that our Relminer project does have some pricing models, but this information is not included yet in the documentation.
Conversation 3
In order to prevent the model from going beyond what’s in our documentation, let’s use the v1 prompt which includes this instruction:
“If the relevant context for the answer is not provided, avoid coming up with logical explanations and just say you don’t know.”
We can run it using the following command, passing the new version of the Prompt.
1
python iteration_0/chatbot.py --mode condense_plus_context --prompt v1
Question: What are the pricing models for relminer ?
The document does not provide information on the pricing models for relminer.
Which is much better and fully aligned with our documentation. Now that we’ve identified a gap in our documentation, let’s use the updated documentation by running our example indicating the “pricing” option for the docs parameters.
1
python iteration_0/chatbot.py --mode condense_plus_context --prompt v1 --docs pricing
Question: What are the pricing models for relminer ?
RelMiner offers three pricing plans …
This is much better and fully aligned with our updated documentation.
Conclusion
Based on the previous interactions, we can distill a few observations:
- Using and understanding our input data (the RelMiner documentation) to ask specific questions, gave us insights about the mistakes the system was doing.
- Don’t simply assume the system will answer the right thing, use a healthy doses of skepticism, and come up with adversarial questions. For example, ask about the things not in your input data, ask about questions that contradict your input data, etc.
- Using the appropriate chat mode for our use case, helped the chatbot to align with our documentation. Experiment with the framework and the options it supports.
- The system tends to go a bit beyond what’s on the documentation, and add sentences which “make sense”. This is good because it gives the user this fluid experience similar to chatting with a person, but it is also bad, because it might answer with wrong statements which might not be aligned with our content.
- Provide clear instructions, and update your prompt as needed to guide the system accordingly (Prompt Engineering). In our case, just instructing the model to refrain from answers when no context was provided, was enough to improve its behavior.
- The system is powerful, and with a small amount of code we could get started quickly, but it also has the tendency of Hallucinating if not configured properly. Fortunately, with minor updates around the system prompt and chat mode, we were able to get much better answers.
Later we’ll cover other aspects around Evals, Monitoring, etc.
Reference
- The LlamaIndex Agents documentation.
- All You Need to Know to Build Your First LLM App