Motivation
This post describes my final project for the Full Stack Deep Learning 2021 Course organized and taught by Sergey Karayev and Josh Tobin.
Problem Statement
Given a dataset such as the Form Understanding in Noisy Scanned Documents (FUNSD) dataset, which provides 199 fully annotated image documents. Would it be possible to train a Machine Learning model to generate similar images with their corresponding annotations? In other words, can we automatically expand this dataset from 199 annotated images, to several thousands of samples without human intervention?
In many cases, the training dataset needed to build models for document understanding, must include every piece of text in the image, its surrounding bounding box coordinates, its relationship with other texts in the image, and other similar metadata. This is usually obtained from worker annotators who spend time providing such detailed metadata. This is costly and slow as there are usually many layouts and document types to work on.
By generating synthetic document images with annotations, we can significantly reduce the time and effort to annotate document images to train models for document understanding.
The idea is to provide synthetic document generation as a service, via a REST API which receives a number of key input parameters, such as number of samples to be generated, etc and returns a serialized representation of the annotations (JSON) and images (base 64 encoded) content.
Machine Learning Approach
The gist of the project is to use a Language Model to generate JSON annotation payloads, which then can be rendered into a document image, giving us fully annotated new document images. The ideal model, could capture the layout and text of the training set encoded in the JSON annotations, and then generate multiple instances of similar documents as well as variations of document layouts. The rendering of the document image from the generated JSON annotations, can be done without ML techniques, as this only involves placing the corresponding text at the given locations, according to the synthetic annotation metadata.
The core model architecture and training loop is an adaptation of the code for Unconditioned Surname Generation available as part of the Natural Language Processing with PyTorch - By Delip Rao and Brian McMahan. (Highly recommended read!)
The basic architecture is defined as:
- One embedding layer (embedding dimension 100)
- One Gated Recurrent Unit (GRU) layer with a hidden dimension of 100
- One fully connected layer with dropout of 0.5
This architecture only represents the Annotation Language Model. In order to provide the final end to end service which produces annotations and images, a model wrapper was needed to sample the Language Model, validate the generated JSON annotations, render and serialize the final document images.
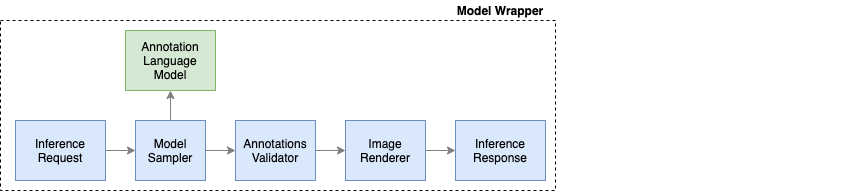
MLOps Approach
Given the focus of the course, the end to end operational aspects of the project are equally important. For this reason, there is an important emphasis on:
- Traceability: Being able to trace model versions, and datasets, and code artifacts precisely as to be able to recover them as needed.
- Repeatability: Being able to bring up the whole environment, and rewind to a given point in time, including infra, code, data, models. Repeat tests, and build on top of previous ones.
- Automation: Embrace everything as code, avoid manual intervention, console access, aim to script each step of the ML workflow.
- Rapid Development: By using automation around all the aspects of the workflow, repetitive steps become easier and faster.
- CPU and GPU: Definitely not required for this small problem, but my goal was to be able to seamlessly train models locally (CPU) and remote (AWS GPU instances).
The technology stack to achieve these goals is:
- Terraform: It allows us to define the infrastructure, including but not limited to: network setup, training instances, databases and security groups as a declarative manifest, which effectively behaves like code. Giving us the chance to tear down and reconstruct the infrastructure as needed.
- Ansible: It allows us to run typical Unix commands on a provisioned AWS EC2 instance to configure it properly, clone our code, and run our training tasks.
- DVC: In this project it was used only to source control datasets and model artifacts via github, using AWS S3 as the artifact store.
- MLFlow: In this project it was used only for model tracking and model deployment. It allows us to keep track of the model training runs, capturing key hyper-parameters and learning curves for traceability, as well as to package our models to run them locally and on Sagemaker.
- Pytorch: The DL library to implement the core ML model as well as training loop and supporting Dataset classes.
- Sagemaker: The service runtime to host our models for inference.
- AWS S3: Use to store datasets, model artifacts.
Data Preprocessing
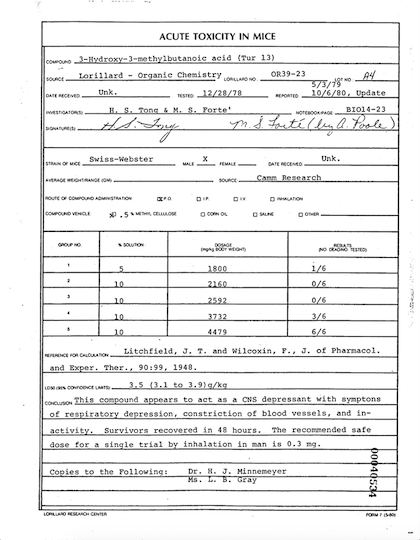
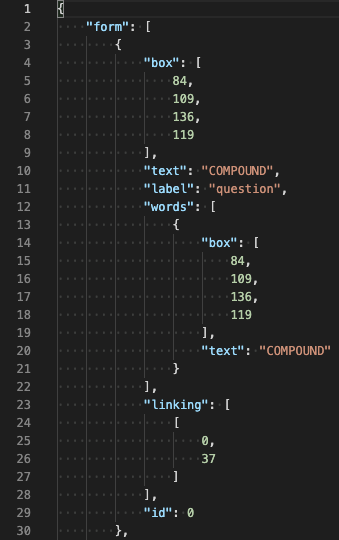
The original FUNSD dataset comes with pairs of annotated images as shown here:
| Image | Annotations |
|---|---|
 |
 |
The initial FUNSD dataset was processed in the following way:
- The annotations were naturally broken into block units, which contain the definition of one piece of text, its bounding box, id, and linkage to other texts.
- In order to reduce the length of the training sequences, these blocks were pre-processed to remove other redundant properties such as the words collection.
- The blocks were flatten-out into strings so the Recurrent Neural Network can process them as single-line sequences.

- The whole dataset was split into: train, validation and test sets and saved into a single csv file.
| train | validation | test |
|---|---|---|
| 5096 | 2315 | 2332 |
- The raw and original datasets were added to DVC for tracking and pushed into external storage (S3).
Model Training
The model was trained on the whole FUNSD pre-processed dataset. Only the JSON annotations where used as features to train the model. Here I describe few of the key hyper-parameters and training aspects:
- Each single-line JSON annotation or “sentence” was wrapped with start and end tokens.
- Sentences were batched into groups of 32 sentences, using a masking token for padding.
- The sentences where not shuffled to preserve the original sequence of the text blocks, and initial page layout.
- Five consecutive validation error drops were use as an early stop mechanism.
- A maximum of 300 epochs was used.
As recommended in the course, the model training was performed in incremental steps, first locally with a small dataset, which provided the opportunity to debug code issues, and check the general trajectory of the optimization process. Later, the model was trained remotely on a AWS EC2 GPU instance. Given the goal of automating everything, this step took significant effort, as I decided to automate the full setup of the remote machine, and run the training modules, and capture and store the trained model artifacts. To actually run the training remotely this following command was used:
1
ansible-playbook train_gru_remote.yaml --ask-vault-pass
This ansible script allowed me to automate the following tasks on the remote machine:
- Configure aws and github credentials
- Clone the project
- Run the train script
- Pushing the model artifacts via DVC
I could literally terminate the GPU instance one day, come next day reprovision it using terraform, and retrain the model with few commands. This allowed me to reduce cost and only have resources around while needed, and at the same time, have no delay in the iterative process of training and improving the model.
MLFlow provided a good way to track all the training runs, for example:
| MLflow Runs |
|---|
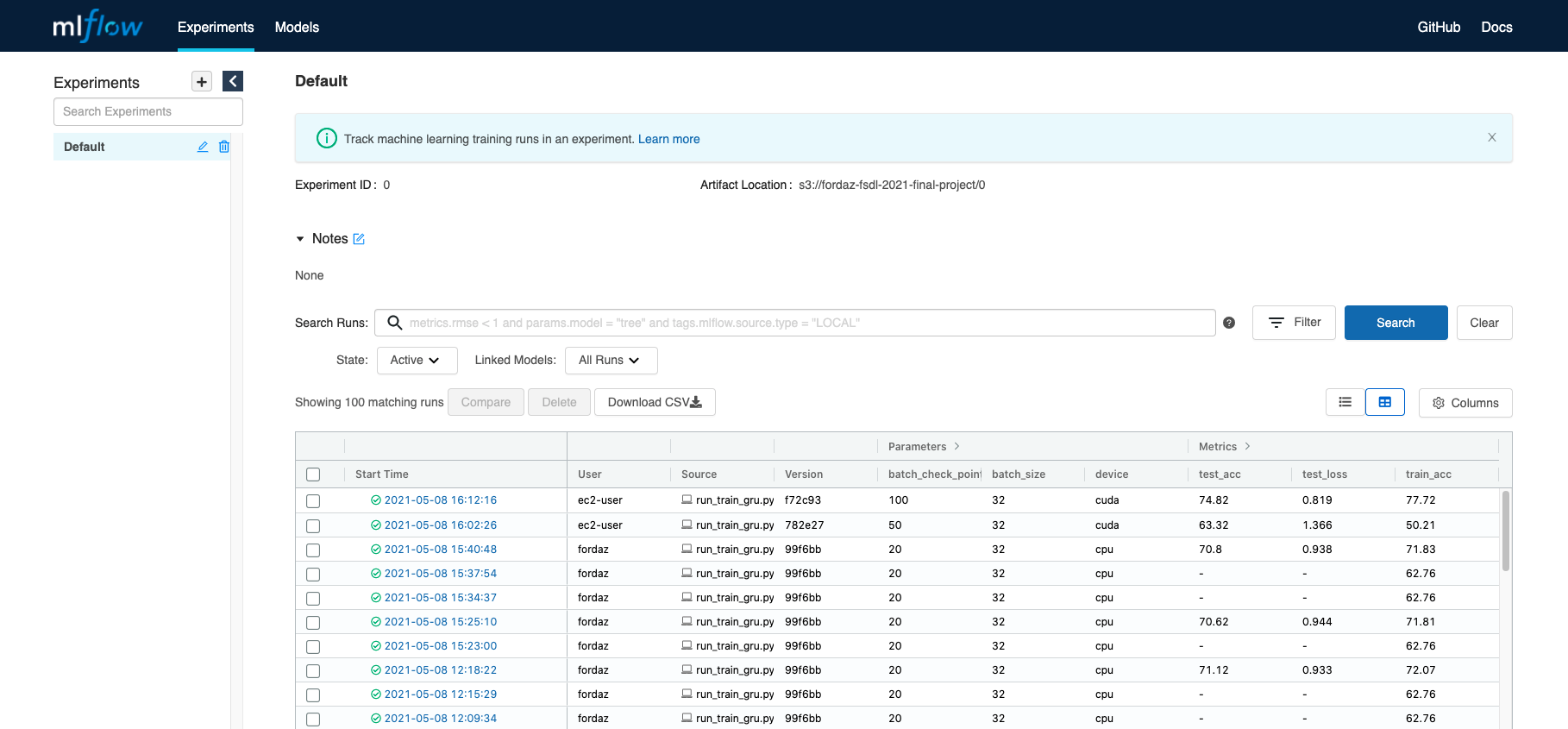 |
It also allows us to drill down into specific runs, and check training parameters and metrics.
| MLflow Parameters and Metrics |
|---|
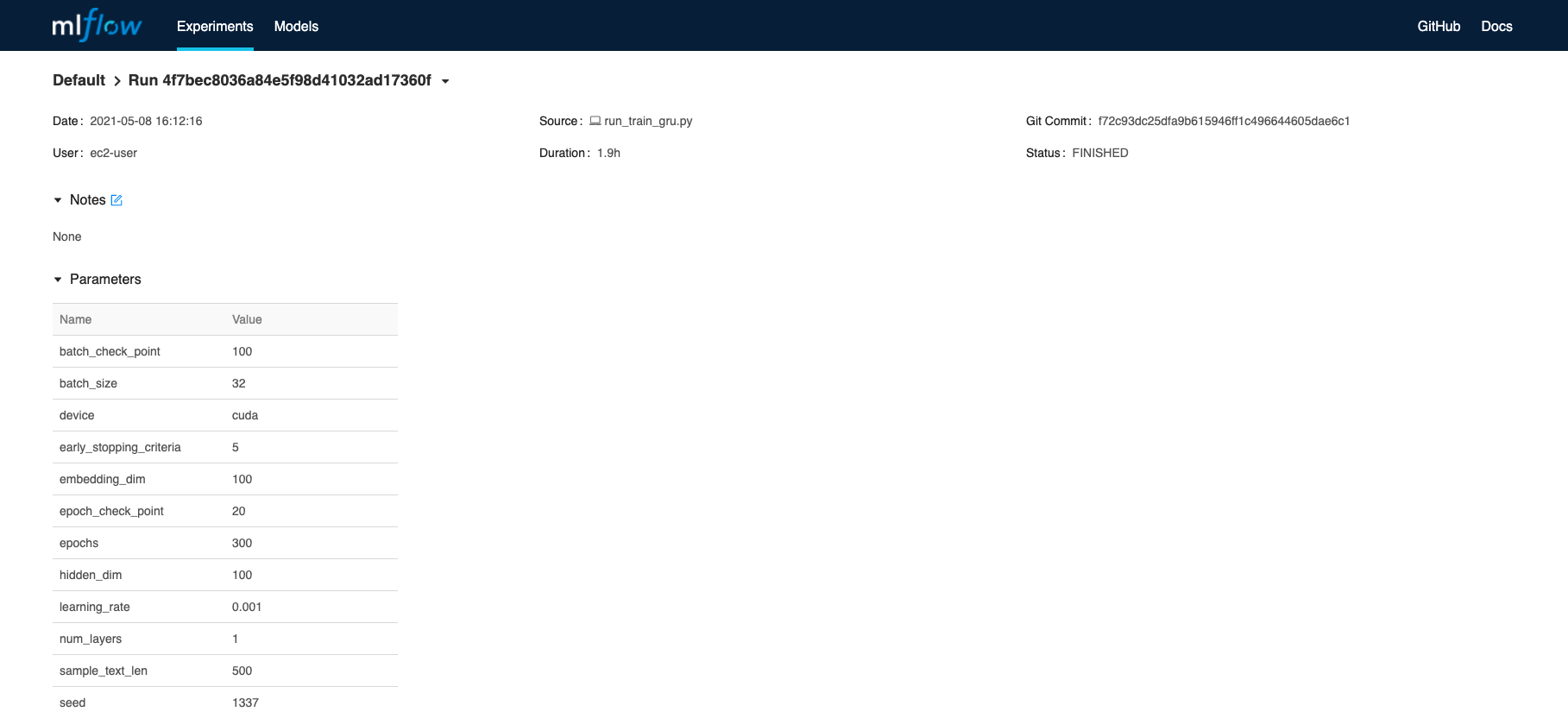 |
 |
Check the learning curves
| MLflow Learning Curves |
|---|
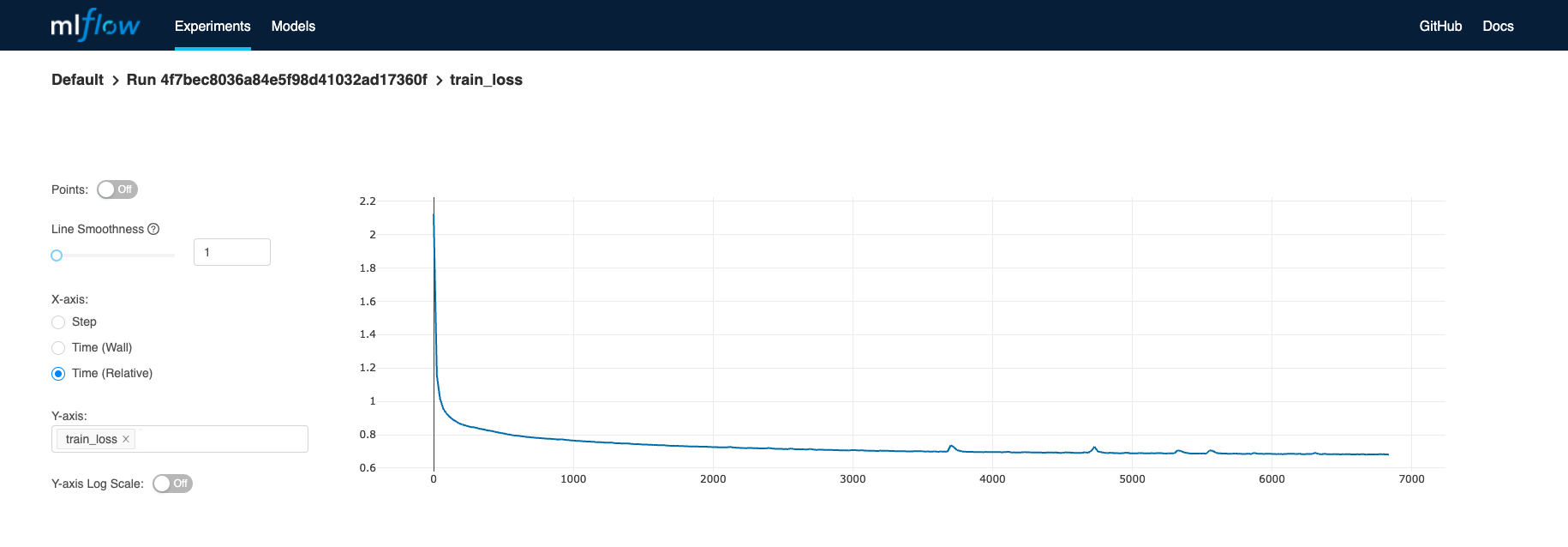 |
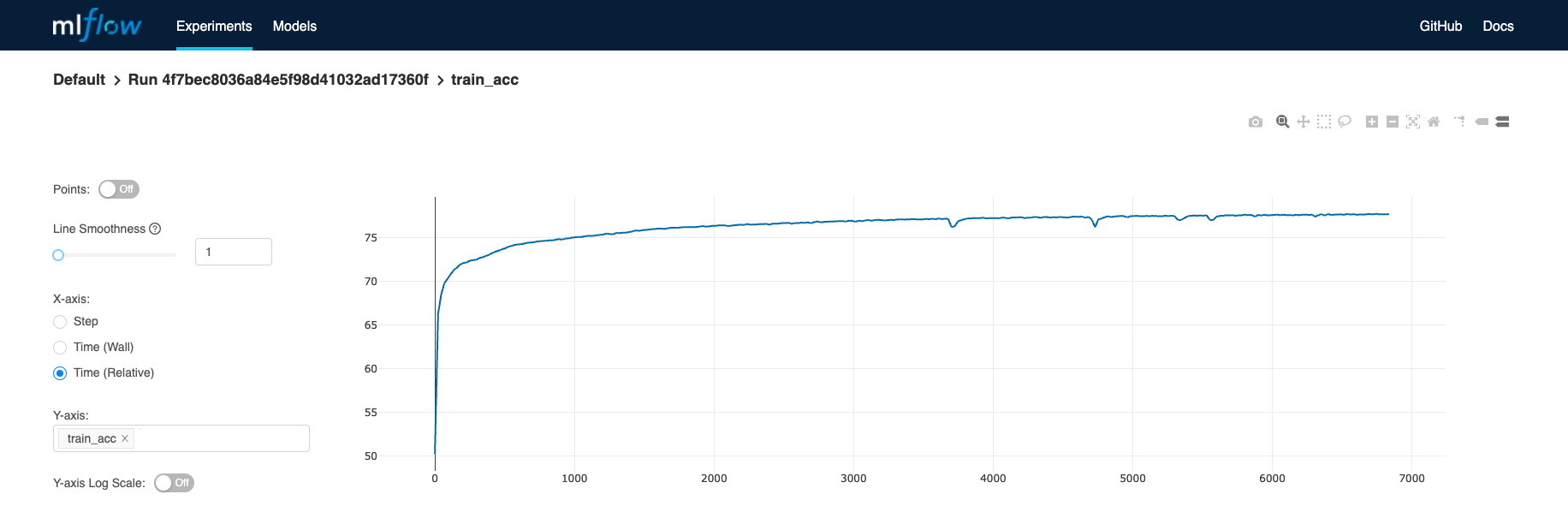 |
As well as comparisons of different runs:
| MLflow Comparing models |
|---|
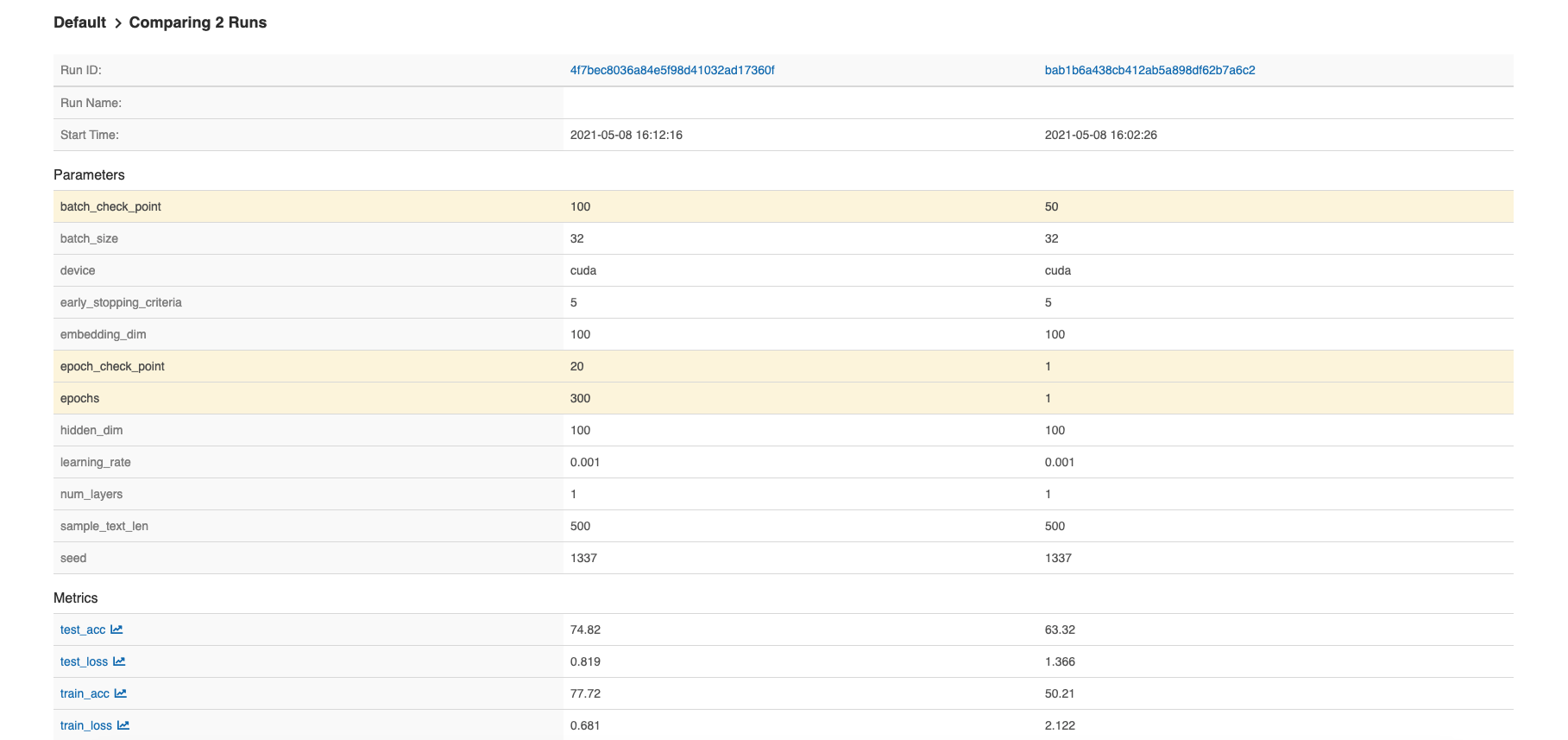 |
Model Evaluation
The trained model was evaluated based on the accuracy of predicting the next character of the JSON annotation, which can be summarized as:
| Train Loss | Val Loss | Test Loss |
|---|---|---|
| 0.681 | 0.777 | 0.819 |
| Train Accuracy | Val Accuracy | Test Accuracy |
|---|---|---|
| 77.72 | 76.07 | 74.82 |
Overall, the model can be improved significantly, but at the same time does not seem to suffer from under/over fitting, and shows a relatively good ability to generalize.
The model was also evaluated by inspecting generated JSON annotations, which seemed to mirror the structure of the training dataset. Here are few generated JSON annotations:
1
2
3
4
5
6
7
8
9
10
11
12
13
{
"text": "Incrur:", "box": [255, 737, 356, 868],
"linking": [], "label": "question", "id": 41
}
{
"box": [175, 717, 223, 740], "text": "Comer",
"label": "question", "linking": [[4, 7]], "id": 3
}
{
"text": "IN TOBIC", "box": [587, 241, 653, 285],
"linking": [], "label": "header", "id": 7
}
...
Model Deployment & Serving
Regarding model packaging, deployment and serving, MLFlow took care of a lot of plumbing, among other things:
- The packaging of both the annotation language model and the model wrapper, as well the the local and remote deployment, exposing a rest endpoint for easy consumption.
1
2
mlflow models serve -p 5001 \
-m model_artifacts/saved_model_baseline_wrapper
-
It also took care of the model input and output standard formats, serialization and deserialization of inputs and outputs, and validation of the input.
-
It allowed me to create an AWS Sagemaker compatible Docker image from the trained model, and register it in AWS ECR.
1
mlflow sagemaker build-and-push-container
- It allowed me to locally test AWS Sagemaker compatible Docker image container for sanity test. This is super useful to find issues in the dependencies and inference code path.
1
2
mlflow sagemaker run-local \
-m model_artifacts/saved_model_baseline_wrapper
- It also allowed to deploy the model image to AWS Sagemaker.
1
2
mlflow sagemaker deploy -a fsdl-synth-docs \
-m model_artifacts/saved_model_local_wrapper -e arn:aws:iam::<rest-of-execution-role>
In this regard, mlflow simplified a lot of the operational overhead, and turned out to be very portable from local to remote deployments.
Analysis
Here are few examples of the outputs of the model:
1
2
3
4
5
6
7
8
{
"box": [677, 639, 749, 669], "text": ".44",
"label": "answer", "linking": [[94, 16]], "id": 35
},
{
"box": [533, 197, 617, 256], "text": "(P2/ 95",
"label": "answer", "linking": [[31, 3]], "id": 3
},
| Synthetic Image | Synthetic Image with Blocks |
|---|---|
 |
 |
1
2
3
4
5
6
7
8
{
"text": "Code Speciop", "box": [49, 975, 160, 799],
"linking": [], "label": "question", "id": 28
},
{
"box": [121, 59, 252, 25], "text": "02328620",
"label": "question", "linking": [[5, 47]], "id": 5
}
| Synthetic Image | Synthetic Image with Blocks |
|---|---|
 |
 |
Looking more closely to the synthetic annotations and images, I noticed:
- It generates many instances of well formed JSON annotations. This indicates the LM was able to learn key structures like:
- Opening and closing brackets: “{, }, [, ]”
- Quoted strings, ex: “text”
- Collections of four integers, ex: “[12,34,23,78]”
- Even unicode text was generated in some instances.
- The model was also able to learn basic JSON properties of the annotations such as: box, text, id, linking, label.
- The final synthetic JSON annotations, were required to be not only well formed JSON, but also including the key JSON properties (box, text, id) of a valid annotation.
- After applying all validations, between 30% and 35% of the synthetic annotations were fully valid.
- Using only the valid generated JSON annotations, and discarding the rest, I was able to avoid any post-processing heuristics to complete or fix them.
- It completely generates random JSON annotations, which is perfect for generating synthetic data.
Other aspects on which the model did not perform well:
- Generates poor bounding boxes, in most cases:
- Too wide for the corresponding text.
- Too tall for the corresponding text.
- The sequence of coordinates left, top, right, bottom was not respected, therefore causing the bounding box to flip.
- After inspecting the ground truth dataset, I noticed the presence of too wide or tall bounding boxes as.
- Text is sometimes on top of each other, and does not follow a good document layout.
- The actual generated document text is not valid english.
Learning & Conclusions
The project was useful as it allowed me to:
- Take a high level idea and see it all the way through a deployed API.
- Experience that end to end ML Based services include many more components and aspects than the core ML Model.
- Experience how some of the tooling can greatly simplify the amount of work (MLFlow rocks!).
- Have the opportunity to learn and refresh a useful set of tools to automate the ML workflow.
In case anyone feels like checking some of the scripts or pieces of code as a study or reference material, here is the source code link.
Further work
This is just scratching the surface of what might be possible to generate synthetic annotated documents.
There are different ways to improve the whole service:
- Do hyper-parameter tuning and improve the performance of the current architecture.
- Try other more powerful models (Transformers, Graph Networks, GANs, etc)
- Explore ideas so the model captures the linking among different blocks of text.
- Explore ideas so the model can use both JSON annotations as well as images to generate and capture a richer representation of the documents.
- Explore ideas so the model supports conditioning, that is, when generating synthetic documents, condition the model to generate certain types of layouts, etc.
- Ultimately the synthetic data should be tried on a downstream task and find out if it actually allows the models to be trained effectively.
- Add realistic image noise using GANs or other image filters.
- Add font types and style variations when rendering the image for more realistic images.
- Update the model wrapper to work for larger batches and generate them into AWS S3, instead of returning them in the HTTP response.